使用专用任务模型提升性能
Open WebUI 提供了多项自动化功能,如标题生成、标签创建、自动补全和搜索查询生成,以增强用户体验。然而,这些功能可能会向您的本地模型同时生成多个请求,在资源有限的系统上可能会影响性能。
本指南介绍了如何通过配置专用的轻量级任务模型或选择性地禁用自动化功能来优化设置,确保您的主要聊天功能保持响应迅速且高效。
为什么 Open WebUI 感觉很慢?
默认情况下,Open WebUI 有几个后台任务,虽然它们让体验变得像魔法一样,但也会给本地资源带来沉重负担:
- 标题生成 (Title Generation)
- 标签生成 (Tag Generation)
- 自动补全生成 (Autocomplete Generation) (此功能在每次按键时触发)
- 搜索查询生成 (Search Query Generation)
这些功能中的每一个都会向您的模型发送异步请求。例如,来自自动补全功能的连续调用可能会显著延迟响应,尤其是在内存或处理能力有限的设备上(例如运行 32B 量化模型的 32GB RAM Mac)。
优化任务模型可以帮助将这些后台任务与您的主聊天应用程序隔离开来,从而提高整体响应能力。
⚡ 如何优化任务模型性能
请按照以下步骤配置高效的任务模型:
第 1 步:访问管理员面板
- 在浏览器中打开 Open WebUI。
- 导航到 管理员面板 (Admin Panel)。
- 点击侧边栏中的 设置 (Settings)。
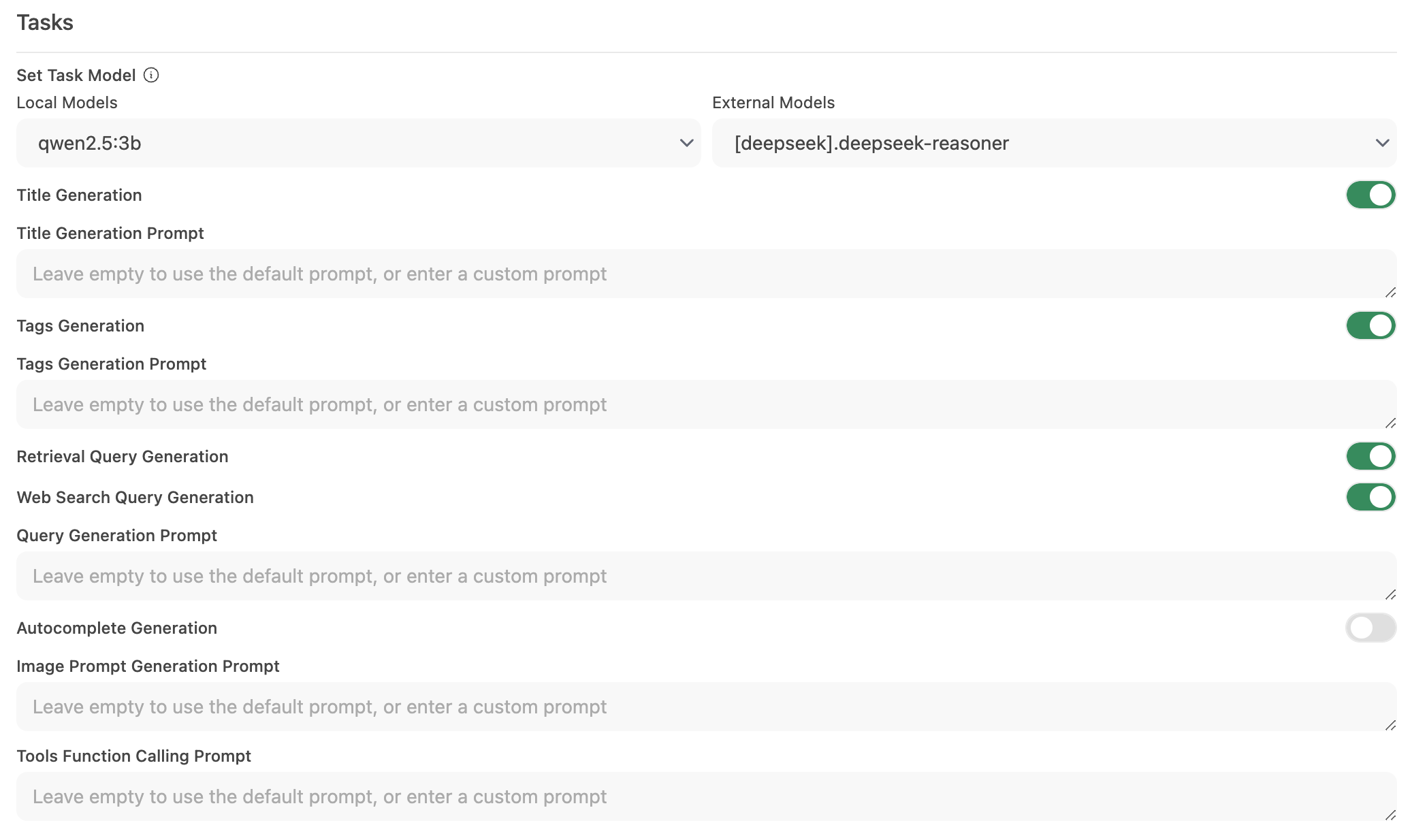
第 2 步:配置任务模型
-
转到 界面 (Interface) > 设置任务模型 (Set Task Model)。
-
根据您的需求选择以下选项之一:
-
轻量级本地模型 (推荐)
- 选择一个紧凑型模型,如 Llama 3.2 3B 或 Qwen2.5 3B。
- 这些模型提供快速响应,同时消耗极少的系统资源。
-
托管 API 端点 (以获得最大速度)
- 连接到托管 API 服务来处理任务处理。
- 这可能非常便宜。例如,OpenRouter 提供的 Llama 和 Qwen 模型价格低于 每百万输入 token 1.5 美分。
OpenRouter 推荐
使用 OpenRouter 时,我们强烈建议在连接设置中配置 模型 ID (允许列表)。导入数千个模型可能会使您的选择器变得混乱并降低管理员面板的性能。
-
禁用不必要的自动化
- 如果不需要某些自动化功能,请禁用它们以减少无关的后台调用——尤其是像自动补全这样的功能。
-
第 3 步:保存更改并测试
- 保存新配置。
- 与聊天界面互动并观察响应速度。
- 如果有必要,通过进一步禁用未使用的自动化功能或尝试不同的任务模型来进行调整。
🚀 本地模型的推荐设置
| 优化策略 | 益处 | 推荐用于 |
|---|---|---|
| 轻量级本地模型 | 最大限度减少资源使用 | 硬件受限的系统 |
| 托管 API 端点 | 提供最快的响应时间 | 拥有可靠网络/API 访问权限的用户 |
| 禁用自动化功能 | 通过减轻负载实现性能最大化 | 专注于核心聊天功能的用户 |
实施这些建议可以极大地提高 Open WebUI 的响应速度,同时让您的本地模型高效地处理聊天互动。
⚙️ 用于性能的环境变量
您还可以通过环境变量配置与性能相关的设置。将这些添加到您的 Docker Compose 文件或 .env 文件中。
其中许多设置也可以直接在 管理员面板 > 设置 界面中进行配置�。环境变量对于初始部署配置或管理多个实例的设置非常有用。
任务模型配置
为后台任务设置专用轻量级模型:
# 用于 Ollama 模型
TASK_MODEL=llama3.2:3b
# 用于 OpenAI 兼容的端点
TASK_MODEL_EXTERNAL=gpt-4o-mini
禁用不必要的功能
# 禁用自动标题生成
ENABLE_TITLE_GENERATION=False
# 禁用后续问题建议
ENABLE_FOLLOW_UP_GENERATION=False
# 禁用自动补全建议 (每次按键触发 - 影响很大!)
ENABLE_AUTOCOMPLETE_GENERATION=False
# 禁用自动标签生成
ENABLE_TAGS_GENERATION=False
# 为 RAG 禁用搜索查询生成 (如果不使用网页搜索)
ENABLE_SEARCH_QUERY_GENERATION=False
# 禁用检索查询生成
ENABLE_RETRIEVAL_QUERY_GENERATION=False
启用缓存和优化
# 缓存模型列表响应 (秒) - 减少 API 调用
MODELS_CACHE_TTL=300
# 缓存 LLM 生成的搜索查询 - 当网页搜索和 RAG 同时激活时,消除重复的 LLM 调用
ENABLE_QUERIES_CACHE=True
# 将 base64 图像转换为文件 URL - 减小响应大小并减轻数据库压力
ENABLE_CHAT_RESPONSE_BASE64_IMAGE_URL_CONVERSION=True
# 批量推送流式 token 以降低 CPU 负载 (高并发时建议:5-10)
CHAT_RESPONSE_STREAM_DELTA_CHUNK_SIZE=5
# 为 HTTP 响应启用 gzip 压缩 (默认启用)
ENABLE_COMPRESSION_MIDDLEWARE=True
数据库与持久化
# 禁用实时聊天保存以获得更好性能 (权衡了数据持久性)
ENABLE_REALTIME_CHAT_SAVE=False
网络超时
# 为慢速模型增加超时时间 (默认:300 秒)
AIOHTTP_CLIENT_TIMEOUT=300
# 获取模型列表的更快超时 (默认:10 秒)
AIOHTTP_CLIENT_TIMEOUT_MODEL_LIST=5
RAG 性能
# 启用并行嵌入以加快文档处理 (需要充足资源)
RAG_EMBEDDING_BATCH_SIZE=100
高并发设置
对于拥有许多并发用户的大型实例:
# 增加线程池大小 (默认是 40)
THREAD_POOL_SIZE=500
有关环境变量的完整列表,请参阅 环境变量配置 文档。
💡 其他提示
- 监控系统资源: 使用操作系统的工具(如 macOS 上的活动监视器或 Windows 上的任务管理器)密切关注资源使用情况。
- 减少并行模型调用: 限制后台自动化可以防止同时发出的请求使您的 LLM 崩溃。
- 尝试不同配置: 测试不同的轻量级模型或托管端点,找到速度与功能之间的最佳平衡点。
- 保持更新: Open WebUI 的定期更新通常包含性能改进和错误修复,因此请保持软件处于最新版本。
相关指南
- 减少内存占用 - 适用于像树莓派这样内存受限的环境
- SQLite 数据库概述 - 数据库架构、加密和高级配置
- 环境变量配置 - 所有配置选项的完整列表
通过应用这些配置更改,您将获得更具响应性和高效的 Open WebUI 体验,让您的本地 LLM 专注于提供高质量的聊天互动,而不会出现不必要的延迟。