OpenAI 兼容服务器使用入门
概述
Open WebUI 不仅仅适用于 OpenAI、Ollama 或 Llama.cpp —— 您可以连接 任何实现了 OpenAI 兼容 API 的服务器,无论该服务器是运行在本地还是远程。如果您想运行不同的大语言模型,或者您已经有了喜欢的后端或生态系统,这将是完美的选择。本指南将向您展示如何:
- 设置 OpenAI 兼容服务器(包含几个常用选项)
- 将其连接到 Open WebUI
- 立即开始聊天
第 1 步:选择 OpenAI 兼容服务器
有许多服务器和工具都暴露了 OpenAI 兼容的 API。以下是一些最受欢迎的选择:
- Llama.cpp: 极其高效,支持 CPU 和 GPU 运行
- Ollama: 超级易用且跨平台
- LM Studio: 适用于 Windows/Mac/Linux 的功能丰富的桌面应用
- Lemonade: 快速的基于 ONNX 的后端,具有 NPU/iGPU 加速功能
选择任何适合您工作流程的工具即可!
🍋 开始使用 Lemonade
Lemonade 是一个即插即用的、基于 ONNX 的 OpenAI 兼容服务器。以下是在 Windows 上尝试它的方法:
-
运行
Lemonade_Server_Installer.exe -
使用 Lemonade 的安装程序安装并下载模型
-
运行后,您的 API 端点将是:
http://localhost:8000/api/v0
详见 其官方文档。
第 2 步:将服务器连接到 Open WebUI
- 在浏览器中打开 Open WebUI。
- 转到 ⚙️ 管理员设置 → 外部集成 → OpenAI。
- 点击 ➕ 添加连接。
- 选择 Standard / Compatible (标准/兼容) 选项卡(如果可见)。
- 填写以下信息:
- API URL: 使用您服务器的 API 端点。
- 示例:
http://localhost:11434/v1(Ollama),http://localhost:10000/v1(Llama.cpp)。
- 示例:
- API 密钥: 除非服务器要求,否则留空。
- API URL: 使用您服务器的 API 端点。
- 点击 保存 (Save)。
如果您在 Docker 中运行 Open WebUI,而模型服务器在宿主机上运行,请使用 http://host.docker.internal:<您的端口>/v1。
对于 Lemonade: 添加 Lemonade 时,请使用 http://localhost:8000/api/v0 作为 URL。
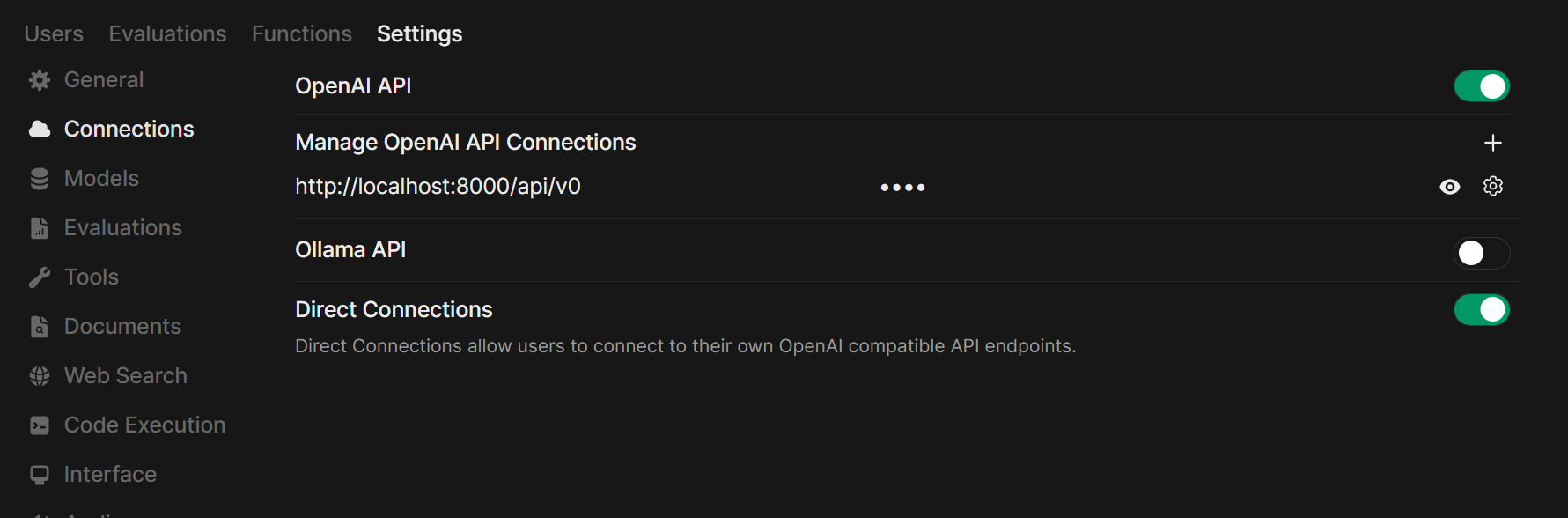
要求的 API 端点
为了确保与 Open WebUI 的完全兼容,您的服务器应实现以下 OpenAI 标准端点:
| 端点 | 方法 | 必填? | 用途 |
|---|---|---|---|
/v1/models | GET | 是 | 用于模型发现并在 UI 中选择模型。 |
/v1/chat/completions | POST | 是 | 聊天的核心端点,支持流式传输和温度等参数。 |
/v1/embeddings | POST | 否 | 如果您想使用此供应商进��行 RAG(检索增强生成),则需要此端点。 |
/v1/audio/speech | POST | 否 | 文本转语音 (TTS) 功能所需。 |
/v1/audio/transcriptions | POST | 否 | 语音转文本 (STT/Whisper) 功能所需。 |
/v1/images/generations | POST | 否 | 图像生成 (DALL-E) 功能所需。 |
支持的参数
Open WebUI 会传递标准的 OpenAI 参数,例如 temperature (温度)、top_p、max_tokens (或 max_completion_tokens)、stop、seed 和 logit_bias。如果您的模型和服务器支持 tools 和 tool_choice 参数,它还支持 工具使用 (Tool Use) (函数调用)。
第 3 步:开始聊天!
在聊天菜单中选择您已连接服务器的模型,然后开始使用!
就是这样!无论您选择 Llama.cpp、Ollama、LM Studio 还是 Lemonade,您都可以轻松地实验并管理多个模型服务器——这一切都在 Open WebUI 中完成。
🚀 尽情享受构建�您完美的本地 AI 设置吧!